Deterministic synthetic data for regulated AI, healthcare, research, software and security workflows.
RadMah AI is the deterministic synthetic-data platform: tabular records, HL7 FHIR R4 healthcare bundles, and industrial OT/ICS simulations from one engine — each run sealed with a cryptographically-chained evidence bundle that is byte-identical under the same seed and verifiable offline. Where tabular-only synthesizers stop, RadMah AI keeps going, so regulated teams can build, test, and share data without touching production PII.
What RadMah AI does
The working surface — what the engine produces, controls and proves in practice.
Tabular synthesis with proven fidelity
The Synthesize engine learns the joint distribution of your CSV or Parquet data — marginals, inter-column correlations, tail behaviour, and rare events — and generates unlimited faithful rows. The flagship core (Differentiable Voronoi Flow Matching, with a Gaussian Copula fallback) scored 95.69% on the public mostlyai-qa benchmark (Adult 24K, 200 epochs) with 99.28% univariate accuracy — a representative result, not a guaranteed outcome for every dataset. Built-in K-S, chi-squared, and Pearson tests run on every job.
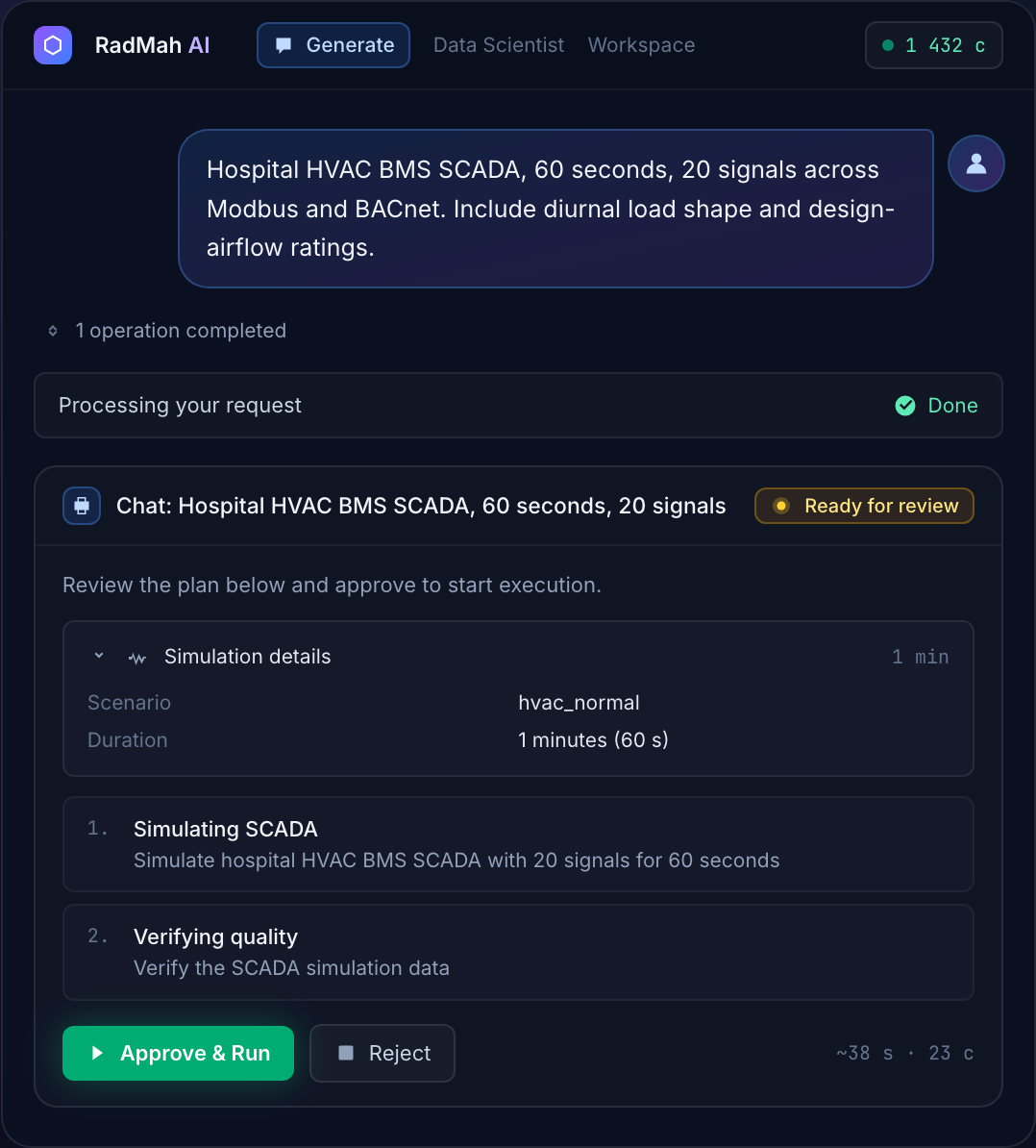
Mock Data from plain English, instantly
Describe what you need in natural language and the AI Assistant drafts a typed schema with domain-aware values (names, addresses, dates, financial, clinical) — sub-minute generation with no uploads or training data. Output is deterministic and reproducible byte-for-byte from a fixed seed.
Constraint-aware generation
Hard business rules are enforced by construction — monotonicity, sum bounds, and referential integrity across joined tables — so financial, clinical, and actuarial datasets obey their domain logic. Feasible contracts produce zero hard-constraint violations; a relation-closure certificate documents referential integrity.
Healthcare FHIR R4 bundles
Generate HL7 FHIR R4 bundles across 8 core resource types (Patient, Encounter, Observation, Condition, MedicationRequest, AllergyIntolerance, Procedure, Immunization) with shipped clinical vocabularies (LOINC, RxNorm, ICD-10-CM), 100% referential integrity, and two-stage structural + conformance validation. Zero PHI by construction.
Industrial OT/ICS simulation
Virtual SCADA and Virtual PLC stream realistic telemetry across 6 live OT protocols — Modbus TCP, OPC-UA, BACnet/IP, MQTT, DNP3, and IEC 61850 (MMS/GOOSE/SCL) — at wire level, with validated industrial physics (ASM1-aligned WWTP, IEEE C57.91 transformer thermal, Arrhenius kinetics), 67 CI-tested plant templates, deterministic fault timing, and cyber-range output (pcapng captures, NDJSON truth/alarm/command streams, Parquet signals).
ICS Security attack-data generation
Generate ground-truth labelled ICS attack datasets mapped to MITRE ATT&CK for ICS (techniques including T0804 Block, T0831 Manipulation of Control, T0832 Manipulation of View, T0836 Modify Parameter, T0856 Spoof) for IDS training, SOC validation, SIEM tuning, and red/blue team exercises — with a true to measured to reported truthfulness pipeline and configurable normal-to-attack ratios.
Autonomous Data Scientist with evidence self-healing
State a goal in natural language; an ICS/OT-aware planner builds a typed multi-step plan across 43 planner tools (data_clean through shap_explain) with an estimated credit cost. A human approval gate precedes any engine run. After each step the agent reads the signed evidence bundle and, if quality, privacy, or constraint metrics fall below threshold, proposes a patch grounded in cryptographically-verified facts — not confidence scores.
Cryptographic evidence bundle on every run
Every job — any engine, any plan — produces a signed .tar.zst bundle: sealed Contract K job spec (schema, constraints, seed), run log, quality report, privacy analysis, lineage, relation-closure certificate, engine SBOM, and a BLAKE3 hash chain binding it all. Given the same Contract K and seed, output is bit-for-bit identical across clusters, and the bundle is verifiable offline with the open-source evidence-verifier CLI — no access to RadMah AI infrastructure or your production data required.
A controlled, evidence-led flow
Define your data contract
Specify schema, constraints, engine, seed, and output format declaratively (Contract K) — or describe it in plain English and let the AI Assistant draft it. The contract is sealed before the run and governs exactly what is produced. Cost gates show estimated credit cost before any expensive operation.
Run the engine
The platform routes the contract to the right capability (Mock Data, Synthesize, Constrained Synthesis, FHIR, Virtual SCADA/PLC, or ICS Security). Generation is deterministic and seed-reproducible, with quality gates (K-S, chi-squared, Pearson, constraint satisfaction, drift) enforced fail-closed during the run.
Receive data plus a sealed evidence bundle
Every run returns the synthetic output and a signed .tar.zst evidence bundle — sealed job spec, run log, quality report, privacy analysis, lineage, relation-closure certificate, engine SBOM, and a BLAKE3 hash chain.
Verify independently
Anyone can confirm bit-for-bit reproducibility and bundle integrity offline using the open-source evidence-verifier CLI — without access to your production data or RadMah AI infrastructure.
What it's used for
Build and test ML without production data
Train and validate models on distribution-faithful synthetic data that preserves marginals and correlations, removing the production-access bottleneck for data science and engineering teams.
Regulated development and data sharing
Generate privacy-safe datasets for development, testing, partner sharing, and cross-border transfer. Synthetic output contains no real records, supporting GDPR Article 89-style data-minimisation strategies; the synthetic set contains no copied source records — confirm cross-border and anonymisation requirements with your own DPO/legal counsel.
Healthcare and clinical research datasets
Produce FHIR R4 bundles with real clinical vocabularies and full referential integrity for EHR integration testing, clinical app development, and research — with zero PHI by construction.
Cyber range and SOC analyst training
Populate cyber ranges with realistic OT telemetry across 6 protocols and inject MITRE ATT&CK ICS-mapped attack traffic to train analysts, tune IDS/SIEM, and run red/blue team exercises.
ICS/OT ML and anomaly-detection datasets
Generate labelled industrial telemetry and attack datasets with correct temporal dynamics and cross-signal correlations for IDS model training and anomaly-detection research across critical-infrastructure verticals.
Audit and regulatory evidence
Hand auditors a cryptographically-sealed evidence bundle that documents provenance, quality, privacy risk, and reproducibility — a compliance deliverable that supports frameworks such as IEC 62443, NERC CIP, and NIST SP 800-82 without exposing production data.
What you receive — and how it's proven
Every job ships with an evidence record, not just an output.
What you receive
- Synthetic tabular data (CSV, Parquet)
- HL7 FHIR R4 bundles across 8 core resource types (LOINC, RxNorm, ICD-10-CM)
- OT/ICS telemetry: pcapng wire captures, NDJSON truth/alarm/command streams, Parquet signal data
- MITRE ATT&CK ICS-mapped, ground-truth-labelled attack datasets
- Signed .tar.zst evidence bundle: sealed Contract K spec, run log, quality report, privacy analysis, lineage graph, relation-closure certificate, engine SBOM, BLAKE3 hash-chain seal
- Quality report: marginal similarity, correlation structure, K-S / chi-squared / Pearson tests, constraint satisfaction, per-column drift
- Privacy analysis: re-identification risk, k-anonymity, singling-out / nearest-neighbour distance
- Determinism proof: BLAKE3 hash establishing bit-for-bit reproducibility
Evidence & proof
- Flagship tabular core scored 95.69% on the public mostlyai-qa benchmark (Adult 24K, 200 epochs) with 99.28% univariate accuracy — cited as a representative example, not a guarantee for any specific dataset
- 9-artifact, BLAKE3-anchored evidence bundle sealed on every job, every engine, every plan — cannot be disabled
- Determinism guarantee: same Contract K and seed yields bit-for-bit identical output across any cluster or future date, with a BLAKE3 determinism proof verifiable offline
- 6 live OT protocols (Modbus TCP, OPC-UA, BACnet/IP, MQTT, DNP3, IEC 61850) with wire-level pcapng output
- Validated industrial physics: ASM1-aligned wastewater, IEEE C57.91 transformer thermal, Arrhenius kinetics; 67 CI-tested plant templates
- FHIR R4 output: 8 core resource types, shipped LOINC/RxNorm/ICD-10-CM vocabularies, 100% referential integrity, two-stage validation
- Synthetic output contains zero real records / zero PHI by construction; privacy risk is measured and reported in the bundle, not assumed
Run it your way
Common questions
Is the 95.69% benchmark a guarantee of quality on my data?
No. 95.69% is a representative result from the flagship engine on the public mostlyai-qa benchmark (Adult 24K, 200 epochs, 99.28% univariate accuracy). Fidelity on your data depends on the dataset; every job ships a quality report (K-S, chi-squared, Pearson, correlation, constraint satisfaction, drift) so you can verify the actual result for your own data.
How do you handle privacy and trust without us taking your word for it?
RadMah AI is built privacy-first: synthetic output contains no real records or PHI by construction, and re-identification risk is measured and reported on every job. Every run also ships a cryptographic evidence bundle your own auditors can verify offline — so trust comes from artifacts you can check, not from a badge.
How do I trust that the synthetic data is reproducible and untampered?
Every run is sealed in a BLAKE3-anchored evidence bundle with a determinism proof. Given the same Contract K and seed, output is bit-for-bit identical across environments, and anyone can verify the bundle and reproducibility offline using the open-source evidence-verifier CLI — no access to your production data or to RadMah AI is required.
Does the synthetic data contain any real records or PII/PHI?
No. Records are statistically derived rather than copied or merely anonymised, so no real individual is representable in the output. Privacy risk (re-identification, k-anonymity, singling-out / nearest-neighbour) is measured and reported in every bundle rather than assumed, supporting GDPR Article 89-style data strategies and cross-border sharing of the synthetic set.
What can RadMah AI do that tabular-only synthesizers cannot?
Beyond tabular synthesis it generates HL7 FHIR R4 healthcare bundles and simulates industrial facilities across 6 live OT protocols with validated physics and MITRE ATT&CK ICS-mapped attack traffic — and seals every run with a cryptographic evidence bundle. It simulates industrial processes, not just data distributions.
Can I run it where my data cannot leave our environment?
Yes. Enterprise offers dedicated cloud, private cloud (AWS/Azure/GCP), on-premise, and air-gapped deployment, plus a signed-container 'data never leaves' delivery on your own network. Managed SaaS is tenant-isolated end-to-end with per-tenant encryption keys.
How RadMah AI relates to the rest of ITLOX
RadMah Sentinel
Governance & evidence around AI data workflows.
AegisWire
RadMah AI supplies validation data for the SOC/ICS use cases AegisWire secures.
Next step